
Главная проблема в омниканальном маркетинге — идентификация пользователя во всех каналах в режиме реального времени. Чаще всего задачу идентификации решают дедупликацией — складывают в хранилище данных все, что есть на момент взаимодействия, и уже потом, в процессе подготовки рассылки или формирования отчетов, пытаются определить, какому пользователю какие данные принадлежат.
Очевидно, что такой подход неэффективен. Ключевые проблемы:
- Поиск профиля пользователя происходит «потом», когда сессия взаимодействия уже завершена. Соответственно, нет возможности использовать данные из других каналов в ходе взаимодействия с пользователем. Не real-time.
- Медленный процесс объединения данных — получение динамического сегмента или ROPO-отчета из мультиканальных данных занимает очень много времени и ресурсов. А настраивать правила в режиме реального времени — совсем невозможно.
Чтобы использовать омниканальные данные на 100% в режиме реального времени, нужно идентифицировать пользователей во всех каналах также в режиме реального времени. Казалось бы, решение простое, но на самом деле нет. Поэтому дедупликация до сих пор существует.
Сложности матчинга пользователей
Матчинг юзеров сначала кажется довольно простой задачей. Казалось бы, в чем проблема? К тебе пришел запрос, котором фигурирует номер телефона? Найди пользователя с таким телефоном и свяжи с ним входящие данные.
Но это легко, если ваша система работает только с одним идентификатором пользователя — только email или только номером телефона. А это возможно в случае, если 100% ваших посетителей/пользователей имеют идентификатор. Если же, скажем, 30% пользователей имеют только номер телефона, 30% имеют только емейл, 20% имеют и телефон и емейл, а остальные вообще ничего не имеют (только что зашли на ваш сайт), сложность возрастает в геометрической прогрессии.
Примеры:
- У вас в базе есть пользователь с
1@example.com. А в запросе от пользователя, про которого вы думали, что у него такой емейл, пришел другой email2@example.com. Это ситуация, когда одним компьютером пользуются больше одного человека. Что делать? - У вас в базе есть пользователь А с
1@example.comи пользователь Б с телефоном+71111111111. А в запросе пришли одновременно1@example.comи+71111111111. Что делать? Объединить два профиля в один? - У вас в базе есть пользователь А с
1@example.comи телефоном+71111111111. И пользователь Б с телефоном+72222222222. В запросе пришли одновременно1@example.comи+72222222222. Что делать?
Мы решили эту проблему, разработав алгоритм идентификации пользователя по двум идентификаторам. Выглядит он так (в конце статьи будет полная схема, доступная для скачивания):
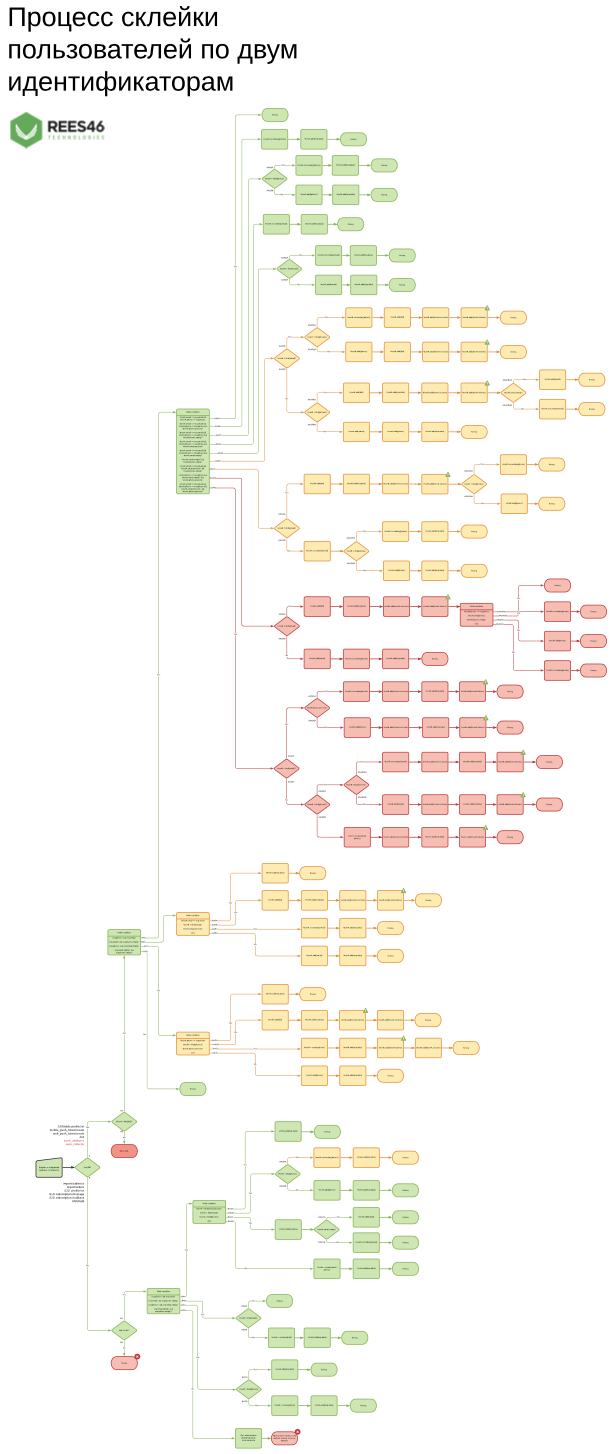
Схема для одного идентификатора выглядит попроще:
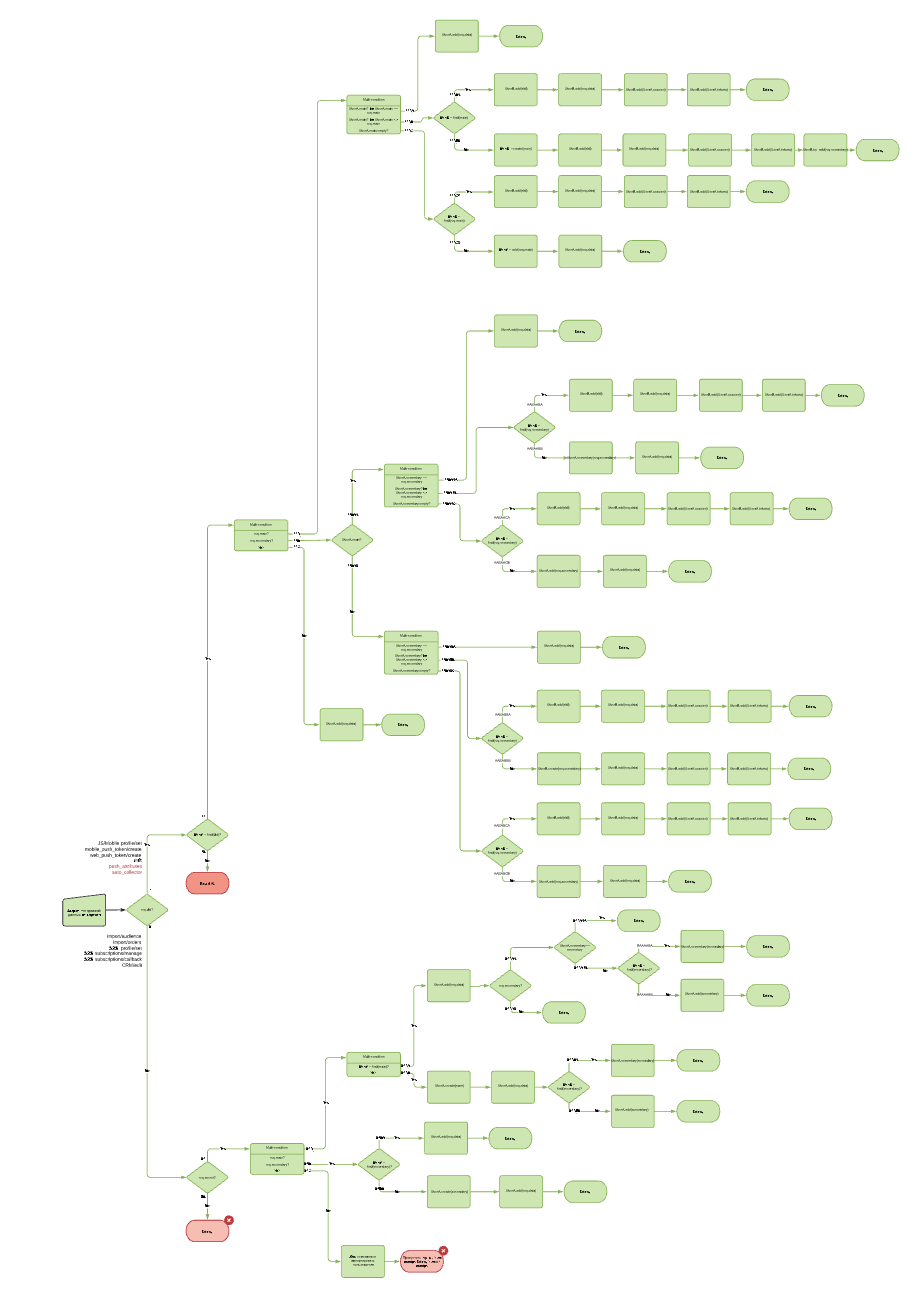
Выглядит запутанно, но мы разберемся. Для начала нужно ознакомиться с терминологией и действующими элементами.
Терминология и действующие лица/предметы
Главная ошибка, которую допускают почти все сервисы: считают cookie идентификатором пользователя. Cookie не может идентифицировать человека. Cookie идентифицирует устройство. Поэтому мы разделяем людей и устройства.
did — идентификатор устройства: cookie, которая ставится на домен клиента и домен нашего API и восстанавливается даже после очистки кук.
client — пользователь, клиент, человек. Идентификатор, который обозначает конкретного живого человека, который в данный момент пользуется устройством.
sid или seance — идентификатор сессии, в ходе которой client на устройстве did взаимодействует с сайтом или мобильным приложением компании. Сессия, как и в Google Analytics, сбрасывается через 40 минут неактивности.
token — токен мобильного или веб-пуша. Ошибочно считается, что токен принадлежит пользователю. Но это не так: токен принадлежит устройству и привязан напрямую к did.
many to many — важный концепт, который должен понимать разработчик CDP и системы матчинга:
- У одного пользователя может быть несколько устройств.
- У одного устройства может быть несколько пользователей.
- У одного устройства может быть только один пользователь в конкретный момент времени.
Идентификатор — идентификатор, по которому можно однозначно определить человека: номер телефона или email. Идентификатором также можно считать номер карты лояльности, но часто бывает, что на одну карту лояльности завязано несколько номеров телефонов, а значит все, что может пойти не так, пойдет не так.
Главный идентификатор — идентификатор, с которого алгоритм начинает поиск пользователя. По умолчанию email.
Второстепенный идентификатор — идентификатор, по которому мы дополнительно ищем либо проверяем пользователя. По умолчанию phone.
Дополнительный контакт — номер телефона или емейл, который является идентификатором у одного пользователя, но имеет отношение и к другому пользователю. Поэтому мы добавляем его в секцию дополнительных контактов.
Источники данных
В зависимости от типа источника данных, они могут прийти как от конкретного устройства (realtime трекинг событий с сайта или мобильного приложения) так и без него (импорт заказов, загрузка аудитории).
Поэтому данные могут приходить как с идентификатором устройства did, так и без него.
Алгоритм
Ниже представлена графическая схема алгоритма склейки по двум идентификаторам.
Пояснения по элементам:
req— данные запросаdid— идентификатор устройства...?— проверка наличия объекта. Напримерreq.did?— проверить, есть ли в запросе свойствоdidUserA— пользователь, которому прямо сейчас принадлежит устройство сdidлибо основной пользователь, найденный на начальных этапах алгоритмаUserBиUserC— дополнительные пользователи, найденные поemailилиphone. В самых сложных ситуациях могут быть найденыUserBиUserCс конфликтующими контактными данными (смотрите красные ветки алгоритмаAAAHиAAAI)AAAHAB— именованные ветки условий в алгоритмах, чтобы проще понимать, по какой ветке пошел алгоритм в конкретной ситуации.UserA.secondary(email)— добавить пользователюAуказанныйemailв дополнительные контакты.UserA.add(email)— добавить пользователюAуказанныйemailкак основной контакт.UserA.add(req.data)— добавить пользователюAданные из запроса (событие, покупка, запрос рекомендаций и так далее).UserB.add(UserA.session)— перенести пользователюBданные из текущей сессии пользователяA(происходит при смене владельца устройства).UserB.add(UserA.tokens)— перенести пользователюBтокены пушей пользователяAтекущего устройства (происходит при смене владельца устройства).
Схемы представлены в виде PDF файлов:
- Основная схема матчинга по двум идентификаторам — работает в REES46 CDP по умолчанию.
- Упрощенная схема матчинга по одному идентификатору — работает в REES46 CDP по запросу, а также будет включена в REES46 Open CDP.
Вопросы и замечания?
Если в схеме есть непонятные или конфликтующие моменты, пишите нам.